

I sottotitoli chiusi sono una tecnica efficace per migliorare l'accessibilità, il coinvolgimento e la conservazione delle informazioni durante presentazioni ed eventi dal vivo. Questo, insieme al cambiamento delle abitudini di consumo video nel settore dello streaming, ha recentemente accelerato l'adozione della sottotitolazione alimentata dall'IA in eventi dal vivo e riunioni aziendali.
Ma quando si tratta di scegliere un fornitore per la propria riunione o evento, la domanda più frequente è: quanto sono accurate i sottotitoli automatici in tempo reale?
La risposta rapida è che, in condizioni ideali, i sottotitoli automatici nelle lingue parlate possono raggiungere fino al 98% di precisione, valutata tramite il tasso di errore delle parole (WER).
E sì, c'è una risposta lunga e leggermente più complessa. In questo articolo desideriamo offrirvi una panoramica su come viene misurata l'accuratezza, quali fattori influenzano l'accuratezza e come portare l'accuratezza a nuovi livelli.
In questo articolo
- Come funziona la sottotitolazione automatica
- Cosa si considera una buona qualità dei sottotitoli?
- Quali fattori influenzano l'accuratezza?
- Misurare l'accuratezza della sottotitolazione automatica
- Comprendere il tasso di errore delle parole (WER)
- Ottenere sottotitoli chiusi incredibilmente precisi per i tuoi eventi in diretta
Prima di immergerci nei numeri, facciamo un passo indietro e osserviamo come funzionano i sottotitoli automatici.
Come funziona la sottotitolazione automatica
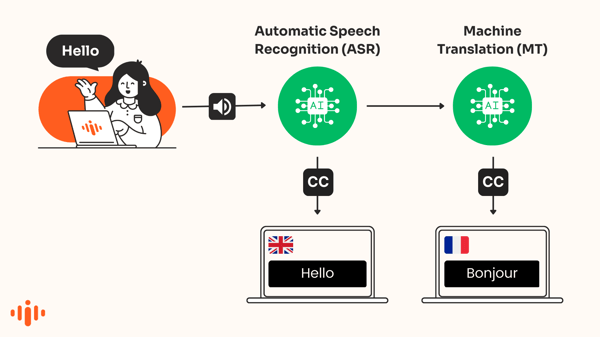
Sottotitoli automatici
I sottotitoli automatici convertono il parlato in testo che appare sullo schermo in tempo reale nella stessa lingua del discorso. ASR - Riconoscimento Automatico del Parlato - è una forma di intelligenza artificiale utilizzata per produrre queste trascrizioni di frasi pronunciate.
La tecnologia, spesso nota come "speech-to-text", è utilizzata per riconoscere automaticamente le parole nell’audio e trascrivere la voce in testo.
Didascalie tradotte dall'IA
I motori di traduzione alimentati dall'IA traducono automaticamente i sottotitoli che appaiono in una lingua diversa. Questo è anche noto come sottotitoli tradotti automaticamente o sottotitoli tradotti da macchina.
Articolo consigliato
Perché dovresti considerare di aggiungere i sottotitoli in diretta al tuo prossimo evento
In questo articolo, trattiamo i sottotitoli automatici. Se desideri conoscere l'accuratezza dei sottotitoli tradotti dall'IA, consulta questo articolo.
Cosa si considera una buona qualità dei sottotitoli?
La Federal Communications Commission (FCC) ha stabilito nel 2014 le caratteristiche essenziali per determinare se i sottotitoli sono "eccellenti":
- Precisione -I sottotitoli devono corrispondere alle parole pronunciate, nella massima misura possibile
- Completezza - I sottotitoli coprono dall'inizio alla fine della trasmissione, nella massima misura possibile.
- Posizionamento - I sottotitoli non bloccano contenuti visivi importanti e sono facili da leggere.
- Sincronizzazione - I sottotitoli si allineano con la traccia audio e appaiono a una velocità leggibile.
Immagine: Sottotitolazione in diretta tradotta dall'IA durante un webinar
Quali fattori influenzano l'accuratezza?
Il motore IA selezionato
Non tutti i motori di riconoscimento vocale producono risultati identici. Alcuni sono migliori in generale, mentre altri sono migliori in alcune lingue. E anche usando lo stesso motore, i risultati possono variare notevolmente a seconda di accenti, livelli di rumore, argomenti, ecc.
Ecco perché, in Interprefy, confrontiamo costantemente i migliori motori per determinare quali producono i risultati più accurati. Di conseguenza, Interprefy può offrire agli utenti la soluzione migliore per una lingua specifica, tenendo conto di aspetti come latenza e costo. In condizioni ideali, abbiamo osservato una precisione costante fino al 98% per diverse lingue.
La qualità dell'input audio
È necessario un input di qualità per la tecnologia di riconoscimento vocale automatizzato al fine di produrre output di qualità. È semplice: più alta è la qualità e la chiarezza dell'audio e della voce, migliori saranno i risultati.
- Qualità audio - Proprio come interpretariato di conferenza, l'hardware audio di scarsa qualità, come i microfoni integrati nei computer, può avere un impatto negativo.
- Pronuncia chiara & articolazione - Presentatori che parlano ad alta voce, con ritmo adeguato e chiaramente, verranno solitamente sottotitolati con maggiore precisione.
- Rumore di fondo - Rumble pesante, cani che abbaiano o fogli che frusciano, catturati dal microfono, possono deteriorare notevolmente la qualità dell'ingresso audio.
- Accenti - I relatori con accenti insoliti o marcati, così come i parlanti non nativi, pongono problemi a molti sistemi di riconoscimento vocale.
- Sovrapposizione del parlato - Se due persone parlano simultaneamente, il sistema avrà molta difficoltà a individuare correttamente l'oratore giusto.
Articolo consigliato
Quanto sono precise le didascalie in Zoom, Teams e Interprefy?
Come misurare l'accuratezza dei sottotitoli automatici
La metrica più comune per misurare l'accuratezza dell'ASR è il Word Error Rate (WER), che confronta la trascrizione reale dell'oratore con il risultato dell'output dell'ASR.
Ad esempio, se 4 parole su 100 sono errate, l'accuratezza sarebbe del 96%.
Comprendere il tasso di errore delle parole (WER)
WER determina la distanza minima tra il testo di una trascrizione generato da un sistema di riconoscimento vocale e una trascrizione di riferimento prodotta da un operatore umano (la verità di base).
WER allinea correttamente le sequenze di parole identificate a livello di parola prima di calcolare il numero totale di correzioni (sostituzioni, cancellazioni e inserimenti) necessarie per allineare completamente i testi di riferimento e di trascrizione. Il WER viene quindi calcolato come rapporto tra il numero di aggiustamenti richiesti e il numero totale di parole nel testo di riferimento. Un WER più basso indica generalmente un sistema di riconoscimento vocale più accurato.
Esempio di Tasso di Errore di Parola: 91,7% di accuratezza
Prendiamo in considerazione un esempio di tasso di errore di parole dell'8.3% - o precisione del 91.7% e confrontiamo le differenze tra la trascrizione originale del discorso e i sottotitoli creati dall'ASR:
| Trascrizione originale: | Output dei sottotitoli ASR: |
| Ad esempio, io faccio solo un uso molto limitato di gli elementi essenziali forniti Vorrei approfondire un punto particolare più in dettaglio temo che io chiamo i parlamenti statali individuali a ratificare la convenzione solo dopo che il ruolo della Corte europea di giustizia sia stato chiarito potrebbe avere effetti molto dannosi. | Ad esempio, io anche vorrei desidero solo un uso molto limitato della esenzioni a condizione che io voglia approfondire un punto particolare, temo che il richiamo sui parlamenti statali individuali per ratificare la convenzione solo dopo che il ruolo della corte europea di giustizia è stato chiarito potrebbe avere effetti molto dannosi. |
In questo esempio, i sottotitoli hanno omesso una parola e sostituito quattro parole:
- Misure: {'matches': 55, 'deletions': 1, 'insertions': 0, 'substitutions': 4}
- Sostituzioni: [('too', 'do'), ('use', 'used'), ('exemptions', 'essentials'), ('the', 'i')]
- Cancellazioni: ['would']
Il calcolo del Word Error Rate è quindi:
WER = (cancellazioni + sostituzioni + inserimenti) / (cancellazioni + sostituzioni + corrispondenze) = (1 + 4 + 0) / (1 + 4 + 55) = 0.083
Il WER ignora la natura degli errori
Ora, nell'esempio sopra, non tutti gli errori hanno lo stesso impatto.
La misurazione WER può risultare ingannevole perché non ci indica quanto sia rilevante/importante un determinato errore. Errori semplici, come l'ortografia alternativa della stessa parola (movable/moveable), non sono spesso considerati errori dal lettore, mentre una sostituzione (exemptions/essentials) può avere un impatto maggiore.
I numeri WER, in particolare per i sistemi di riconoscimento vocale ad alta precisione, possono essere fuorvianti e non corrispondono sempre alle percezioni umane di correttezza. Per gli esseri umani, le differenze nei livelli di precisione tra il 90% e il 99% sono spesso difficili da distinguere.
Tasso di errore delle parole percepito
Interprefy ha sviluppato una metrica proprietaria e specifica per lingua di errore ASR chiamata Perceived WER. Questa metrica conta solo gli errori che influenzano la comprensione umana del discorso e non tutti gli errori. Gli errori percepiti sono solitamente inferiori al WER, a volte anche fino al 50%. Un WER percepito del 5-8% è generalmente quasi impercettibile per l'utente.
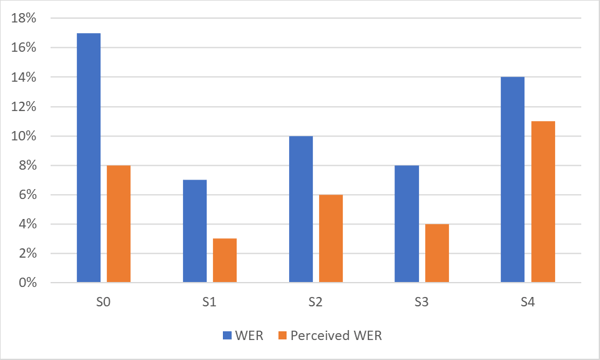
Il grafico sottostante mostra la differenza tra WER e Perceived WER per un sistema ASR altamente accurato. Nota la differenza di prestazioni per diversi set di dati (S0-S4) della stessa lingua.
Come mostrato nel grafico, il WER percepito dagli esseri umani è spesso sostanzialmente migliore rispetto al WER statistico.
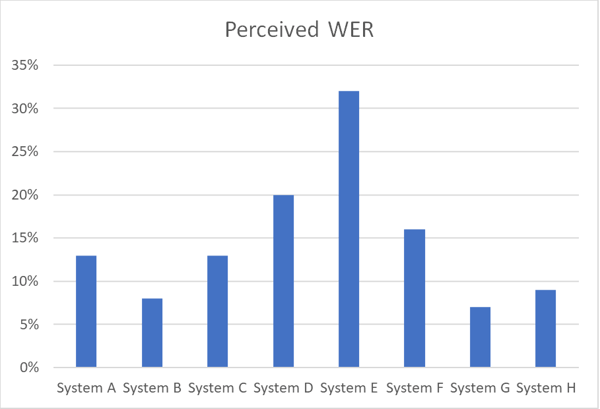
Il grafico sottostante illustra le differenze di precisione tra vari sistemi ASR che lavorano sullo stesso set di dati vocali in una certa lingua usando il Perceived WER.
Ottenere sottotitoli chiusi incredibilmente precisi per i tuoi eventi in diretta
Abbiamo riscontrato un'accuratezza del 97% per i nostri sottotitoli automatici grazie alla combinazione della nostra soluzione tecnica unica e alla cura che dedichiamo ai nostri clienti. Alexander Davydov, Responsabile della Consegna AI presso Interprefy
Se sei' alla ricerca di sottotitoli automatici altamente precisi durante un evento, ci sono tre aspetti chiave da considerare:
Utilizza una soluzione di eccellenza
Invece di scegliere un motore pronto all'uso per coprire tutte le lingue, opta per un fornitore che utilizzi il miglior motore disponibile per ogni lingua nel tuo evento.
Interessato a capire cosa può offrirti il miglior motore? Leggi il nostro articolo: Il futuro dei sottotitoli in tempo reale: come l'AI di Interprefy potenzia l'accessibilità
Ottimizza il motore
Scegli un fornitore in grado di integrare l'IA con un dizionario personalizzato per garantire che i nomi di marca, i nomi insoliti e gli acronimi vengano catturati correttamente.
Assicurare un ingresso audio di alta qualità
Se l'input audio è di scarsa qualità, il sistema ASR non sarà in grado di garantire una qualità dell'output. Assicurati che il discorso venga catturato in modo forte e chiaro.


 Altri link per il download
Altri link per il download



